I ran into numerous problems when using tools such as fio and filebench to measure file system performance. Furthermore, these tool primarily measure the number of megabytes transferred to and from disk. My goal with this project is to measure the relative performance overhead the file system adds. For example, if I had thousands of small files with multiple workers, which file system should I use with my disk subsystem?
The Testing Strategy
The application employ several distinct workload patterns:
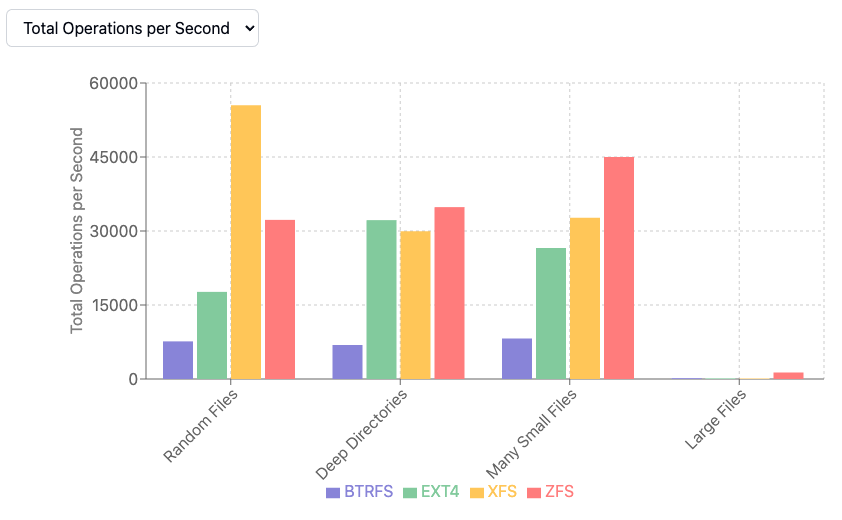
Random File Creation: Files of varying sizes are distributed across a directory structure of moderate depth. This simulates the behaviour of applications which generate output files, temporary data, or cached content without strict organisational constraints.
Deep Directory Structures: We construct hierarchical directory trees of significant depth, then populate them with files. This pattern reflects the organisation of source code repositories, nested configuration directories, or hierarchical data storage schemes.
Many Small Files: A concentrated effort to create numerous files of minimal size within a constrained directory structure. This workload approximates the behaviour of systems which fragment data into many small components—consider email storage systems, or applications which maintain extensive metadata collections.
Large File Operations: Though not our primary focus, we include tests involving files of substantial size to ensure our measurements capture the full spectrum of filesystem behaviour.
Concurrency
A filesystem which performs admirably under single-threaded access may exhibit quite different characteristics when subjected to concurrent operations. Modern systems rarely operate in isolation; multiple processes, threads, and users compete for filesystem resources simultaneously.
The testing methodology employs multiple concurrent workers, each operating independently within its own portion of the filesystem hierarchy. This approach serves two purposes: first, it more accurately reflects the concurrent nature of modern computing; second, it exposes performance characteristics which might remain hidden under purely sequential testing.
Each worker operates with its own random seed, ensuring that the patterns of file creation and directory traversal differ between workers, thus avoiding artificial synchronisation, which might skew results.
Filesystems
Different filesystem implementations take different approaches. XFS, designed for large-scale server deployments, optimises for scalability and large file handling. EXT4 represents a mature, general-purpose approach with broad compatibility. ZFS brings advanced features such as built-in compression and snapshot capabilities, though at the cost of increased complexity. BTRFS offers similar advanced features with a different implementation strategy.
The testing framework treats these filesystems as interchangeable backends, applying identical workloads to each. This approach allows for direct comparison of their relative strengths and weaknesses under our specific test conditions.
The code is available on GitHub mtelvers/fsperf.
Next Steps
Add filessystem specific features such as snapshots and clones to the testing matrix. Ref A ZFS Scaling Adventure